2026年3月26日,人工智能学院在15栋315召开了科研三组例会,杨老师汇报了课题组在强化学习方向的研究进展,重点介绍了为解决策略梯度算法训练不稳定、样本效率低等问题所设计的PPO算法框架。主要内容如下:
一、会议内容
1、研究背景与核心问题
当前,传统的策略梯度方法(如REINFORCE)存在高方差、收敛慢的问题,而基于价值函数的方法(如DQN)难以处理连续动作空间和高维状态空间。早期的信赖域方法(TRPO)虽然通过约束策略更新幅度保证了稳定性,但其计算复杂度高、实现困难。PPO算法旨在在保持TRPO稳定性的同时,大幅简化实现难度并提升计算效率。本研究聚焦于复杂决策任务(如机器人控制、游戏AI、自动驾驶)的策略学习,其核心挑战在于:
(1)如何在保证策略稳定更新的前提下,允许较大的步长以提高样本效率,避免策略崩溃。
(2)如何实现裁剪机制与自适应目标函数的平衡,使算法既能探索又能利用,同时防止策略过早收敛到次优解。
(3)如何处理多轮迭代中的策略退化问题。连续交互过程中,旧策略与新策略的差异累积可能导致价值估计偏差增大,提出的"PPO"算法与关键技术。
汇报重点介绍了OpenAI提出的近端策略优化(Proximal Policy Optimization)框架。
(1)裁剪替代目标函数(Clipped Surrogate Objective)
利用改进的替代目标函数替代TRPO中的复杂约束优化。核心思想是在目标函数中引入裁剪机制,限制新策略与旧策略的概率比值的变动范围。
设计了一种自适应的裁剪参数ϵ (通常取0.1或0.2),构建目标函数:
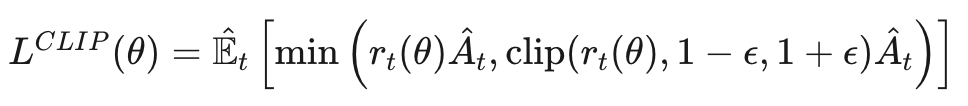
该设计确保策略更新既不会过于激进(避免性能崩溃),也不会过于保守(保证学习效率),实现了"信赖域"效果的近似。
(2)广义优势估计(GAE)与值函数联合训练
构建了一个可微分的critic网络,与actor策略网络同步更新。框架运行机制为:策略网络处理当前状态,输出动作概率分布;Critic网络估计状态价值函数V(s),用于计算优势函数。通过GAE方法平衡偏差与方差,形成"采样-评估-更新"闭环。GAE公式为:
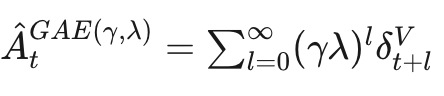
(3)多轮小批量更新机制
为应对样本利用效率问题,框架包含一个数据复用单元。收集固定长度的轨迹数据后,对同一批数据进行多轮(通常为4-8轮)小批量随机梯度下降。当策略与旧策略的KL散度超过阈值时,提前终止当前批次更新,实现自适应的更新强度控制。
3、初步验证与应用场景
(1)基准环境验证
在OpenAI Gym的连续控制任务(MuJoCo)上,PPO算法在样本效率和最终性能上媲美TRPO,同时实现难度显著低于基线方法,能够在HalfCheetah、Walker2d等环境中稳定达到专家级表现。
(2)拟探索的真实世界场景
机器人运动控制:从仿真到现实的迁移学习中,PPO作为基础策略优化器,结合域随机化技术,实现四足机器人的稳健步态生成。
大语言模型对齐(RLHF):结合人类反馈数据,使用PPO优化语言模型的生成策略,使其输出更符合人类价值观和偏好,成为ChatGPT等系统的核心技术之一。
实时游戏AI:在星际争霸、Dota2等复杂多智能体环境中,作为底层策略优化模块,支持大规模并行训练与快速策略迭代。
二、组员讨论
汇报结束后,与会老师与同学围绕框架的可行性、挑战及下一步方向展开了热烈讨论:
许小迪老师提出计算复杂度关切。她指出,可微符号推理和实时知识库更新可能带来较大的计算开销,尤其是在处理超大规模概念集时。建议在下一阶段工作中,引入知识蒸馏或规则重要性剪枝策略,对符号部分进行“瘦身”。
李琳老师关注规则的可信度与冲突解决问题。他提问,当从数据中归纳出多条相互矛盾或置信度不高的规则时,推理循环如何进行仲裁与决策?建议引入不确定性量化和证据理论,为每条规则赋予动态权重。
王利元老师从工程落地角度,建议明确框架的阶段性产出。他认为应先聚焦于一个相对封闭的基准问题(如某类棋类游戏的策略学习),完整验证闭环的有效性,再扩展至开放的复杂系统,这样更容易评估框架的核心贡献。
三、会议总结
杨老师对本次汇报和讨论进行了总结。
会议肯定了PPO算法设计的简洁性和在深度强化学习领域的价值,一致认为策略裁剪机制是解决策略梯度不稳定问题的有力路径。
同时,会议明确指出当前工作仍处于算法复现与基准测试阶段,面临样本效率、探索能力、真实环境迁移等多重挑战。

图为例会讨论现场
